This post describes how to setup a single-node Hadoop Cluster.
- Installing Java ( OpenJDK ) and Open SSH Server
- Check if Java is already installed by typing java -version in the terminal
- If you have OpenJDK version greater than 1.6, then fine. Or else install it by from terminal.
- NOTE: Open software center, go to edit tab, Software Sources and choose all.
- sudo apt-get install openjdk-7-jdk
- Check using java -version in the terminal. // remember to write update alternatives if other java versions are installed.
- Install Open SSH Server using sudo apt-get install openssh-server
- Adding a new user.
- sudo addgroup hadoop ( hadoop is a group)
- sudo adduser -ingroup hadoop hduser ( hduser is the new user )
- Add hduser to sudo group to have all rights - sudo adduser hduser sudo
- See below image (press enter to leave blank some fileds)

- Configure SSH access.
- Install SSH server- sudo apt-get install openssh-server
- Switch to hduser in terminal using su - hduser
- Type ssh-keygen -t rsa -P "" ( just press enter when asked for where to save the key.)
- To enable SSH access, copy those keys into your home folder using this command. ( use id_dsa if rsa.pub doesn't exist )
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys - See below image.
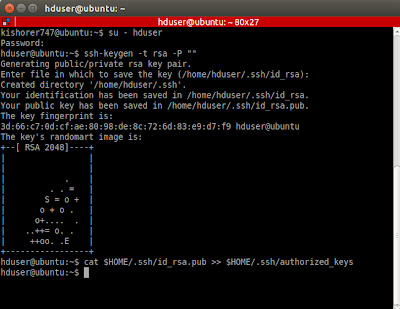
- Test if it works by typing in the terminal ssh hduser@localhost ( enter hduser's password )
- See below image.

- Disabling IPv6
- Open config file: sudo gedit /etc/sysctl.conf
- Add these 3 lines at the end of the file:
#disable ipv6; net.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1 net.ipv6.conf.lo.disable_ipv6 = 1- Hadoop Installation
- Download Hadoop tar file from apache mirror here - http://apache.mirrors.pair.com/hadoop/common/hadoop-2.4.1/hadoop-2.4.1.tar.gz
- Extract it, rename the folder to hadoop.
- Change directory in Terminal to the parent folder where you have extracted hadoop.
For example - cd /home/kishorer747/Downloads/ - Command to move - sudo mv hadoop /usr/local/
- Now own the folder to give all the permissions for hduser using sudo chown -R hduser:hadoop /usr/local/hadoop
- Setting Global Variables.
- In .bashrc file, profile file and environment file. Do this for both the users. Copy into all 3 files once from normal user in terminal and once again from hduser)
- Open these files and add following lines at the end. NOTE: Update your Java version in the variable JAVA_HOME.
- After adding the following code, test by typing echo $HADOOP_HOME and echo $JAVA_HOME ( should show home path )
sudo gedit ~/.bashrc
sudo gedit ~/.profile
sudo gedit /etc/environment# Set Hadoop-related environment variables export HADOOP_PREFIX=/usr/local/hadoop export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=${HADOOP_HOME} export HADOOP_COMMON_HOME=${HADOOP_HOME} export HADOOP_HDFS_HOME=${HADOOP_HOME} export YARN_HOME=${HADOOP_HOME} export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop # Native Path export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib" #Java path export JAVA_HOME='/usr/local/Java/jdk1.7.0_65' # Add Hadoop bin/ directory to PATH export PATH=$PATH:$HADOOP_HOME/bin:$JAVA_PATH/bin:$HADOOP_HOME/sbin- Configuring hadoop Configuration files.
- Change directory using cd /usr/local/hadoop/etc/hadoop
- Open yarn-site xml file and replace with the following lines -
sudo gedit yarn-site.xml



- Open core-site xml file and replace with the following lines
sudo gedit core-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
hadoop.tmp.dir /app/hadoop/tmp A base for other temporary directories. fs.default.name hdfs://localhost:54310 The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.
- Open mapred-site xml file and replace with the following lines
sudo gedit mapred-site.xml
mapred.job.tracker localhost:54311 The host and port that the MapReduce job tracker runs at. If "local", then jobs are run in-process as a single map and reduce task.
- Open hdfs-site xml file and replace with the following lines
sudo gedit hdfs-site.xml
dfs.replication 1 Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time.
- Create some directories.
sudo mkdir -p $HADOOP_HOME/yarn_data/hdfs/namenode
sudo mkdir -p $HADOOP_HOME/yarn_data/hdfs/datanode
- Testing Time !! ( IMPORTANT: Run all these commands from hduser. )
- Own the hadoop folder again.
- Go to bin folder ( cd /usr/local/hadoop/bin ) and format the namenode ( works from any where as we have added hadoop bin folder to System path earlier )-
sudo chown -R hduser:hadoop /usr/local/hadoop hadoop namenode -format- Exit status should be 0. Else, you messed up somewhere. Look if somewhere permission denied is there in between, and if it is folder cannot be created, you have to own that folder again.
- See below images for sample output of the command hadoop namenode -format



- Go to sbin folder start all daemons. ( cd /usr/local/hadoop/sbin )
start-all.sh
- To check what daemons are running, use this command in terminal ( from hduser )- jps
- If any daemon doesn't start, start them manually
hadoop-daemon.sh start namenode hadoop-daemon.sh start datanode yarn-daemon.sh start resourcemanager yarn-daemon.sh start nodemanager mr-jobhistory-daemon.sh start historyserver
- Hadoop Web Interfaces.
- Namenode - http://localhost:50070/
- Secondary Namenode - http://localhost:50090
- Most important is jps. Use jps to check which daemons are running.
No comments:
Post a Comment